| CoreParse.py Generating XML Schemas from the sample Core Component catalog |
|
| # This script creates XML schemas from
tables of Core Components. ## coreparse.py version 12/17/2001 http://www.gldialtone.com/coreparse.htm # Syntax: Coreparse FILENAME (COMPONENT) where FILENAME is the name of # your input file without extension, and COMPONENT is your optional top-level # element, if you only want an XSD schema of one component and its children. # Example: "CoreParse CC4" will open input file CC4.XML, and generate CC4.XSD. # Download python from http://www.python.org/download/ # Read python howto: http://py-howto.sourceforge.net |
ARRAY STRUCTURE # 0 UID # 1 DictionaryEntryName # 2 CCTused # 3 BasicOrAggregate # 4 definition # 5 remarks # 6 ObjectClass # 7 PropertyTerm # 8 RepresentationTerm # 9 BusinessTerms # 10 CoreComponentChildren # 11 (XML datatype) # 12 (levels of depth) # 13 (dependency flag) |
UN/CEFACT and groups such as X12 are defining standard data elements for e-business interactions, based on decades of semantics work in EDI and e-business. They are not close to agreement; however, groups such as UBL and the AIAG are publishing Core Components in ebXML standard "core component" format, in the near term.
Core Components format is based on ISO 11179. ISO 11179 is a standard for metadata definition, in a quarrelsome world where software vendors and users must inevitably agree on conceptual meanings of data elements, but do not agree on anything else (platforms such as *nix, win*, languages C/Java, etc., syntax such as SQL, EDI, XML, structure/relationships in the data, etc.) All ISO standards are copyrighted, therefore we have this little game where it pops up and disappears from various websites. (download, download)
Core Components are syntax-independent. Their meanings are locked in place by user requirements and the need for legal enforceability.
Core Components are the master data, not UML models or XML vocabularies, or anything else.
The purpose of Coreparse.py is to downgrade/ export Core Components into particular W3C XML Schemas, HTML, and in future, sample XML instances and XMI.
The two tables which specify Core Component Types and their content models are not found in the Word table of sample core components -the Types and Content are found only in the PDF file of the CC specification, so I had to enter them manually into a table prior to this point. These are the "base classes".
Table 6-3 Representation Terms
Table 6-2 CCT Content and Supplementary Components
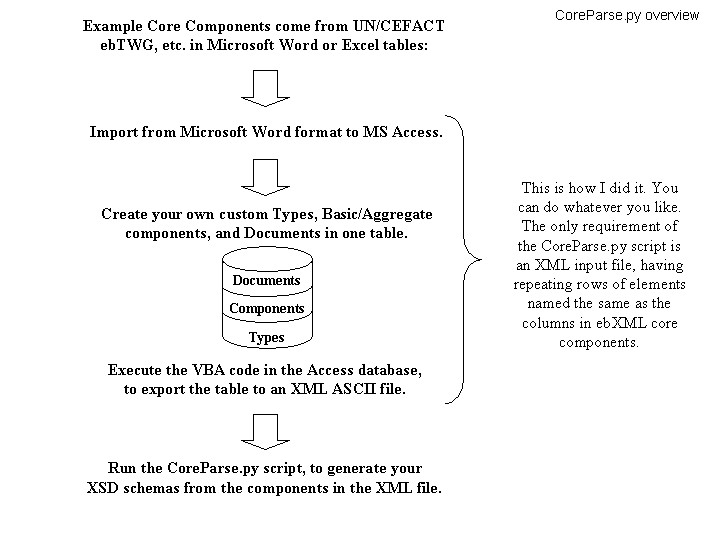
Import the tables from access or word, into an XML file using XML spy or other tool, or if you are using our Access GLcoreComponentsV?.mdb, execute the VBA command to export Core Components from the table to XML. One element will be on each row of the table; each row of the table will result in one <row> instance as below. The coreparse.py script hunts for the tag, <UID>, etc. in sequence. All element names should be prepared with column headings in the Catalog with whitespace eliminated. An example follows.
<Import>
<Row>
<UID>000001</UID>
<DictionaryEntryName>Party. Details</DictionaryEntryName>
<CCTused>n/a</CCTused>
<BasicOrAggregate>Aggregate</BasicOrAggregate>
<definition>Details of an individual, a group or a body having a role in a business function.</definition>
<remarks/>
<ObjectClass>Party</ObjectClass>
<PropertyTerm>n/a</PropertyTerm>
<RepresentationTerm>Details</RepresentationTerm>
<BusinessTerms/>
<CoreComponentChildren>Party. Identifier (000016) Party. Description. Text (000009) Party. Type. Code (000002) Person. Details (000095) Organisation. Details (000096)</CoreComponentChildren>
</Row>
<Row>
<UID>000002</UID>
<DictionaryEntryName>Party. Type. Code</DictionaryEntryName>
...
example Core Components have come from UN/CEFACT ebXML, ebTWG, etc. in Word or Excel format:
|
UID |
Dictionary Entry Name |
CCT Used |
Basic or Aggregt |
definition |
remarks |
Object Class |
Property Term |
Represent |
Business Terms |
Core Component Children |
|
000009 |
Party. Description. Text |
Text. Type |
Basic |
Text providing information on the party. |
This text may cover information which is in addition to the structured information but cannot be provided within the given structure |
Party |
Description |
Text |
|
|
|
000001 |
Party. Details |
n/a |
Aggregate |
Details of an individual, a group or a body having a role in a business function. |
|
Party |
|
Details |
|
- Party. Identifier (000016) |
|
000016 |
Party. Identifier |
Identifier. Type |
Basic |
A character string used to uniquely identify and distinguish a party. |
|
Party |
Identification* |
Identifier |
|
|
|
000002 |
Party. Type. Code |
Code. Type |
Basic |
The characteristics of a party which is independent of its role. |
this can be used to distinguish legal entities from individual persons or a group of people |
Party |
Type |
Code |
|
|
| ...Etc. |
Remember, these sample components from UN/CEFACT are not final and might be miles away from whatever they are currently discussing in their private discussions. The game plan for SMEs (small/medium enterprises) is, changing the metadata framework of our applications to prepare for Core Components, so that we can compete with giant corporations and their software vendors when Core Components are published. So, we should get used to being DICTATED a core components vocabulary, in table format, and constructing our own business documents and types around those.
The script works as follows.
# STEP 1: Import all Core Components rows into an 11-column array.
# STEP 2: Cleanup the big array, get rid of rows with empty UIDs, etc.
# STEP 3: Create additional lists (names and types), for each component.
# STEP 4: Convert column 11 (child elements) strings into python lists.
# STEP 5: Build "type images" -- XML scraps for Table 6-2 Content types.
# STEP 6: Flag the Aggregate core components having 1 or 2 levels
# STEP 6a: some quick validation checks on Aggregate elements.
# STEP 6b: Analyze the Aggregate core components having 1 or 2 levels.
# STEP 6c: Determine the depth of Aggregate core components 3-5 levels deep.
# STEP 6d: Determine dependencies (identify elements to include in a custom XSD.)
# STEP 7a: Write an XML Schema-- prolog and Basic core components:
# STEP 7b: Write XML Schema Types for Aggregate components no Aggregate children elements.
# STEP 7c: Write XML Schema Types for Aggregate components having children that are Aggregates.
# STEP 8a: Write HTML header/prolog to document the same core components in HTML.
# STEP 8b: Write all the data elements/components into an HTML table.
1. The script will eliminate all whitespace
from DictionaryEntryName
and all other places where dot-space notation is used such as
CoreComponentChildren. For
example, "Party. Type. Code"
becomes "Party.Type.Code".
Note that this process DOES introduce a remote possibility of name clash if
users create Component with almost identical names like "Sharename.
Text" and "Share name. Text".
2. The script will type each Core Component into XML based on the last term of its DictionaryEntryName (which corresponds with one of the 16 Permissible Representation Terms, Table 6-3, not CCT Types! ). This preserves separate types Date and Time, since this is an XML Schema implementation of Core Components, we preserve the original intent of any Core Component of type Date or Time.
Accordingly the script uses all of the 16 Representation Terms as Types from Table 6-1. As a result of this, it's necessary to add six CCT Types to the input file of Core Components before running the script:
Name
= same as Text
Percent
= same as Numeric
Date
= same as Date Time. Type
except that the Date. Type
is restricted to Dates only.
Time
= same as Date Time. Type
except that the Time. Type
is restricted to Times only.
Rate
= same as Numeric
Value
= same as Numeric
As a result of this, it's also necessary to add four CCT Types to the input file of Core Components before running the script:
Date. Content
Date. Format. Text
Time. Content
Time. Format. Text
3. The core component types finally boil down to the lowest level/atomic components in Table 6.2. To control the output of the script, these have been entered into the GLcoreComponentsV091.mdb just like the Basic and Aggregate core components, XML Schema types into the <XMLdatatype> column of the input file of Core Components before running the script. Remember, the script wants to find:
string - xsd:string
decimal - xsd:decimal
binary - xsd:anyURI
Here is what the Python script produces in the Dec 17 2001 version.
<xs:complexType name="Party.Identifier">
<xs:annotation><xs:documentation>
A character string used to uniquely identify and distinguish a party.
</xs:documentation></xs:annotation>
<xs:sequence>
<xs:element name="Identifier.Content"
type="xs:string"/>
<xs:element name="IdentificationScheme.Name"
type="xs:string" minOccurs="0" maxOccurs="1"/>
<xs:element name="IdentificationSchemeAgency.Name"
type="xs:string" minOccurs="0" maxOccurs="1"/>
<xs:element name="Language.Code" type="xs:string" minOccurs="0" maxOccurs="1"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="Person.Given.Name">
<xs:annotation><xs:documentation>
The given name, first name, Christian name or moniker of a person.This applies only to parties being natural persons
</xs:documentation></xs:annotation>
<xs:sequence>
<xs:element name="Text.Content" type="xs:string"/>
<xs:element name="Language.Code" type="xs:string" minOccurs="0" maxOccurs="1"/>
</xs:sequence>
</xs:complexType>
As you can see, the script is NOT regarding the CCTs such as Text.Type as complex types. Instead it is baking Text.Content and Language.Code directly into the XML Schema according to the content model in Table 6-2 CCT Content and Supplementary Components.
4. The script concatenates the definition
and remarks fields into a single <annotation><documentation> element in
the XML Schema.
5. The script imports these fields but does not, at present, do anything
with these fields when building the XML Schema. It only uses them when building
HTML tables.
ObjectClass
PropertyTerm
RepresentationTerm (other than
to ensure it equals the suffix in DictionaryEntryName
)
BusinessTerms
6. Elements having CoreComponentChildren must be parsed into complex types, as you saw in the above. Other elements are well-formed even if parsed into elements in the root element. Some elements contain CoreComponentChildren having children whose names end with ". Details". Those children must, themselves, be parsed.
Each Representation Term is composed of lowest-level Content models, which can all be loaded into the same table with BCCs, ACCs, BBIEs and ABIEs. As far as I can see, they are all the same stuff, with a few particular differences in how the rows would be handled in generating XML schemas.
Since an aggregate CC can use other Aggregates, an entire business document can be assembled from CC. In other words you can put business documents as well as CCs in the registry.
Thus, with the database (Catalog) of Core Components just as it is today, and as it is incrementally changed tomorrow, all elements and their composition can be stored in a single array in memory. With RAM at $100/Gbyte who needs an RDBMS for this. This could be done in C or COM or Java or VB its so easy.
What began life as an MDB file, became a
mini-registry, containing all of your metadata in the same flat memory array in
Python. look
ma, no assembly.
XML Documents
Core Components
Types and Content models
I am not claming this is right-- the Core Component specification has a more
complex technical architecture, in which Documents will be assembled under
Assembly Rules http://www.ebxml.org/specs/
and http://www.ebxml.org/specs/ebCCDOC_print.doc
and http://www.ebtwg.org/projects/core.html
. taking into account six dimensions of context which are really six different
vocabulary domains.
Building these XSD schemas will at least, be useful in investigating relationships
that may exist, and producing documentation, transforming to web pages, and of course developing and testing sample XML instance docs. I cannot imagine how a low-budget shop could test their instance docs
without XML schemas and a validating XML parser..The real base class of each Core Component seem to be its Representation Term, rather than the 11 CCTs (Core Component Types) which the Representation Term is based on.
What really needs to be discussed are the issues now being raised in UBL Definition archives, e.g. the XML Extension Mechanism, the Thoughts on ebXML Classes paper, Rawlin's Position Paper on code lists, the Elements versus Attributes document, Schema modularization - “include” and “import”etc.
Core Components list archives http://lists.ebtwg.org/archives/ebtwg-ccs/ ,
UBL Definition archives http://lists.oasis-open.org/archives/ubl-ndrsc/
,
UBL Library archives http://lists.oasis-open.org/archives/ubl-lcsc/
,
XFront best practices http://www.xfront.com/BestPracticesHomepage.html
, and
UBL file trove, http://www.oasis-open.org/committees/ubl/ndrsc/input/
Note. See IdType-DocType.htm , the full listing of allComponents.htm, and coreParse.htm for important information about this implementation.
TB